Understanding the evaluation process¶
In this post, we are going to explain how to evaluation process happens and how to use different validation strategies.
Parameters¶
The GASearchCV class, expects a parameter named cv.
This stands for cross-validation and it accepts any of the scikit-learn
strategies, such as K-fold, Repeated K-Fold, Stratified k-fold, and so on.
You can find more about this in scikit-learn documentation.
A second parameter that comes along, is the scoring, this is the evaluation metric that the model is going to use, to decide which model is better, it could be for example accuracy, precision, recall for a classification problem or r2, max_error, neg_root_mean_squared_error for a regression problem. To se the full list of metrics, check in here
Steps¶
The way as GASearchCV evaluates the candidates is as follows:
It starts by selecting random sets of hyperparameters according the the param_grid definition, the total number of sets is determined by the population_size parameter.
It fits a model per each set of hyperparameters and calculates the cross validation score according to the cv and scoring setup.
After evaluating each candidate, the fitness, fitness_std, fitness_max and fitness_min are computed and are logged into the console if
verbose=True. Fitness is the way to refer to the selected metric, but this is calculated as the average of all the candidates of the current generation, this means that if there are 10 different set of hyperparameters, the fitness value, is the average score of those 10 evaluated candidates, the same goes for the others metrics.Now it creates new sets (generation) of hyperparameters, those are created by combining the last generation with different strategies, those strategies depends on the selected
algorithms.It repeats the step 2, 3 and 4 until the number of generations is met, or until a callbacks stops the process.
At the end, the algorithm selects the best hyperparameters, as the one set that got the best individual cross validation scoring.
Those steps could be represented like this, each line represents one of several possible natural process like mating, crossover, selection and mutation:
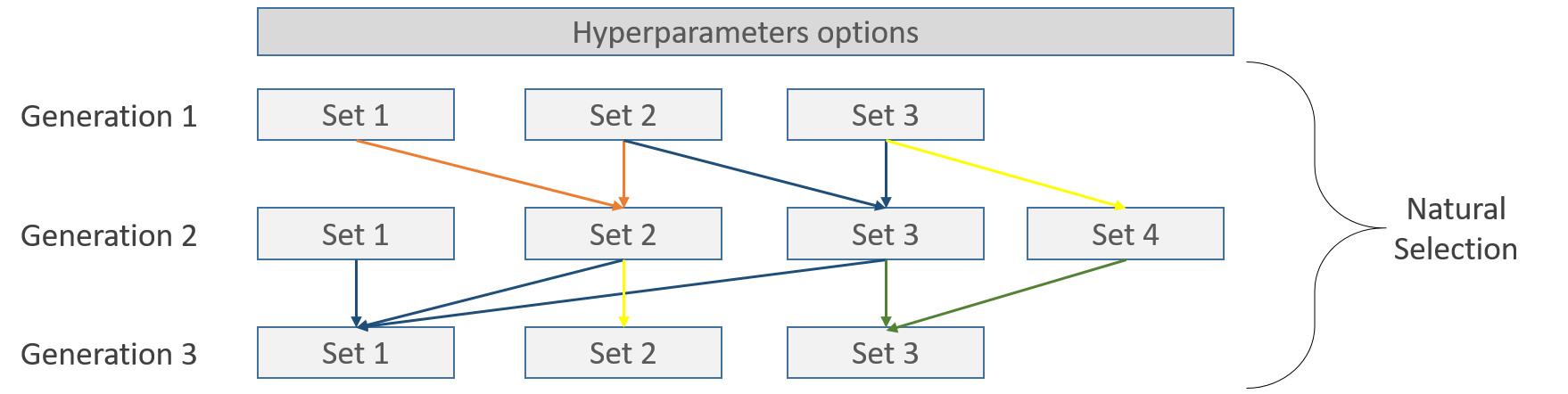
Inside each Set, the cross validation takes place, for example using 5-Folds strategy
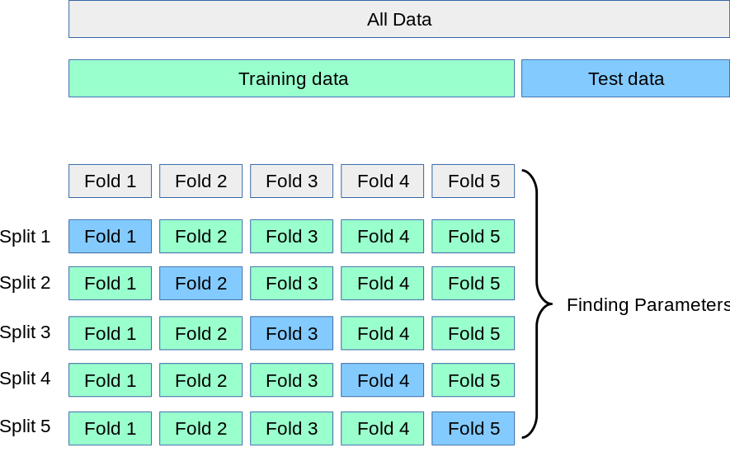
Image taken from scikit-learn
Example¶
This example is going to use a regression problem from the Boston house prices dataset. We are going to use an K-Fold with 5 splits taking as evaluation metric the r-squared.
At the end, we are going to print the top 4 best solutions and the r-squared on the test set for the best set of hyperparameters.
from sklearn_genetic import GASearchCV
from sklearn_genetic.space import Integer, Categorical, Continuous
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split, KFold
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import r2_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
data = load_boston()
y = data["target"]
X = data["data"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
cv = KFold(n_splits=5, shuffle=True)
clf = DecisionTreeRegressor()
pipe = Pipeline([('scaler', StandardScaler()), ('clf', clf)])
param_grid = {
"clf__ccp_alpha": Continuous(0, 1),
"clf__criterion": Categorical(["mse", "mae"]),
"clf__max_depth": Integer(2, 20),
"clf__min_samples_split": Integer(2, 30),
}
evolved_estimator = GASearchCV(
estimator=pipe,
cv=3,
scoring="r2",
population_size=15,
generations=20,
tournament_size=3,
elitism=True,
keep_top_k=4,
crossover_probability=0.9,
mutation_probability=0.05,
param_grid=param_grid,
criteria="max",
algorithm="eaMuCommaLambda",
n_jobs=-1,
)
evolved_estimator.fit(X_train, y_train)
y_predict_ga = evolved_estimator.predict(X_test)
r_squared = r2_score(y_test, y_predict_ga)
print(evolved_estimator.best_params_)
print("r-squared: ", "{:.2f}".format(r_squared))