Feature Selection With Noisy Iris Data
This notebook keeps the original goal of the Iris feature-selection tutorial: use GAFeatureSelectionCV to find a compact subset of useful features. The example now adds synthetic noise features so the selection problem is more realistic.
Menu
Problem Setup
The original Iris dataset has only four informative features. To make feature selection visible, we add random noise columns. A useful selector should keep a small subset of original measurements and avoid most noise columns.
We use a Pipeline with StandardScaler and SVC because SVMs are sensitive to feature scale.
[1]:
import warnings
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score, balanced_accuracy_score, classification_report
from sklearn.model_selection import StratifiedKFold, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn_genetic import (
EvolutionConfig,
GAFeatureSelectionCV,
OptimizationConfig,
PopulationConfig,
RuntimeConfig,
)
from sklearn_genetic.callbacks import ConsecutiveStopping, DeltaThreshold, TimerStopping
from sklearn_genetic.schedules import ExponentialAdapter, InverseAdapter
warnings.filterwarnings("ignore", category=UserWarning)
RANDOM_STATE = 42
rng = np.random.default_rng(RANDOM_STATE)
[2]:
iris = load_iris(as_frame=True)
X_original = iris.data
y = iris.target
noise = pd.DataFrame(
rng.normal(size=(X_original.shape[0], 12)),
columns=[f"noise_{index:02d}" for index in range(12)],
)
X = pd.concat([X_original, noise], axis=1)
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.30,
stratify=y,
random_state=RANDOM_STATE,
)
cv = StratifiedKFold(n_splits=3, shuffle=True, random_state=RANDOM_STATE)
print(f"Original features: {X_original.shape[1]}")
print(f"Noise features: {noise.shape[1]}")
print(f"Total features: {X.shape[1]}")
Original features: 4
Noise features: 12
Total features: 16
Baseline With All Features
The baseline trains on all original and noise columns. This gives us a reference for whether feature selection preserves model quality while reducing the feature set.
[3]:
def make_svc_pipeline():
return Pipeline(
[
("scaler", StandardScaler()),
(
"svc",
SVC(
kernel="rbf",
C=2.0,
gamma="scale",
random_state=RANDOM_STATE,
),
),
]
)
def evaluate(estimator, X_eval, y_eval):
predictions = estimator.predict(X_eval)
return {
"accuracy": accuracy_score(y_eval, predictions),
"balanced_accuracy": balanced_accuracy_score(y_eval, predictions),
}
baseline = make_svc_pipeline()
baseline.fit(X_train, y_train)
baseline_metrics = evaluate(baseline, X_test, y_test)
baseline_metrics
[3]:
{'accuracy': 0.8222222222222222, 'balanced_accuracy': 0.8222222222222223}
Configure GAFeatureSelectionCV
GAFeatureSelectionCV searches over binary masks. A value of 1 means the feature is selected; a value of 0 means it is excluded.
This configuration uses several optimizer controls:
PopulationConfig(initializer="smart")starts from diverse masks instead of purely random masks.max_features=6asks the optimizer to find a compact subset.OptimizationConfig(diversity_control=True)boosts exploration when the population collapses or stalls.OptimizationConfig(fitness_sharing=True)reduces pressure for many similar masks to dominate too early.OptimizationConfig(local_search=True)performs a small final neighborhood search around strong masks.adaptive schedules gradually change crossover and mutation behavior during the run.
[4]:
selector = GAFeatureSelectionCV(
estimator=make_svc_pipeline(),
cv=cv,
scoring="balanced_accuracy",
max_features=6,
evolution_config=EvolutionConfig(
population_size=20,
generations=15,
crossover_probability=ExponentialAdapter(initial_value=0.8, end_value=0.4, adaptive_rate=0.15),
mutation_probability=InverseAdapter(initial_value=0.30, end_value=0.08, adaptive_rate=0.25),
tournament_size=3,
elitism=True,
keep_top_k=3,
),
population_config=PopulationConfig(initializer="smart"),
runtime_config=RuntimeConfig(n_jobs=-1, parallel_backend="auto", use_cache=True, verbose=True),
optimization_config=OptimizationConfig(
local_search=True,
local_search_top_k=2,
local_search_steps=1,
local_search_radius=0.15,
diversity_control=True,
diversity_threshold=0.30,
diversity_stagnation_generations=3,
diversity_mutation_boost=1.8,
random_immigrants_fraction=0.10,
fitness_sharing=True,
sharing_radius=0.40,
),
)
callbacks = [
DeltaThreshold(threshold=0.001, generations=5, metric="fitness_best"),
ConsecutiveStopping(generations=7, metric="fitness_best"),
TimerStopping(total_seconds=90),
]
selector.fit(X_train, y_train, callbacks=callbacks)
gen evals avg best div unique stag mut sel events
---- ----- ------------- ------------- ------- ------- ----- ------- ----- ------------------
0 20 0.58725 0.96128 0.053 1.000 0 - - -
1 40 0.75526 0.96128 0.053 0.750 1 0.200 3 div,imm=4,dup=15,s
2 40 0.84625 0.96128 0.053 0.750 2 0.256 3 div,imm=4,dup=10,s
3 40 0.85387 0.96128 0.053 0.650 3 0.304 3 div,imm=4,dup=10,s
4 40 0.86208 0.96128 0.053 0.650 4 0.345 3 div,imm=4,dup=6,sh
INFO: DeltaThreshold callback met its criteria
INFO: Stopping the algorithm
[4]:
GAFeatureSelectionCV(crossover_probability=<sklearn_genetic.schedules.schedulers.ExponentialAdapter object at 0x00000226B432D7F0>,
cv=StratifiedKFold(n_splits=3, random_state=42, shuffle=True),
diversity_control=True, diversity_mutation_boost=1.8,
diversity_stagnation_generations=3,
diversity_threshold=0.3,
estimator=Pipeline(steps=[('scaler', StandardScaler()...
final_selection_top_k=3,
final_selection_cv=None),
population_config=PopulationConfig(initializer='smart',
warm_start_configs=[]),
population_size=20,
runtime_config=RuntimeConfig(n_jobs=-1,
pre_dispatch='2*n_jobs',
error_score=nan,
return_train_score=False,
use_cache=True,
parallel_backend='auto',
verbose=True),
scoring='balanced_accuracy', sharing_radius=0.4)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| estimator | Pipeline(step...m_state=42))]) | |
| cv | StratifiedKFo... shuffle=True) | |
| scoring | 'balanced_accuracy' | |
| population_size | 20 | |
| generations | 15 | |
| crossover_probability | <sklearn_gene...00226B432D7F0> | |
| mutation_probability | <sklearn_gene...00226B432D6A0> | |
| max_features | 6 | |
| keep_top_k | 3 | |
| n_jobs | -1 | |
| evolution_config | EvolutionConf...MuPlusLambda') | |
| population_config | PopulationCon...rt_configs=[]) | |
| runtime_config | RuntimeConfig... verbose=True) | |
| optimization_config | OptimizationC...ction_cv=None) | |
| local_search | True | |
| local_search_top_k | 2 | |
| local_search_radius | 0.15 | |
| diversity_control | True | |
| diversity_threshold | 0.3 | |
| diversity_stagnation_generations | 3 | |
| diversity_mutation_boost | 1.8 | |
| fitness_sharing | True | |
| sharing_radius | 0.4 | |
| tournament_size | 3 | |
| elitism | True | |
| verbose | True | |
| criteria | 'max' | |
| algorithm | 'eaMuPlusLambda' | |
| refit | True | |
| pre_dispatch | '2*n_jobs' | |
| error_score | nan | |
| return_train_score | False | |
| log_config | None | |
| use_cache | True | |
| parallel_backend | 'auto' | |
| population_initializer | 'smart' | |
| local_search_steps | 1 | |
| random_immigrants_fraction | 0.1 | |
| adaptive_selection | False | |
| selection_pressure_min | 2 | |
| selection_pressure_max | None | |
| offspring_diversity_retries | 0 | |
| sharing_alpha | 1.0 |
Fitted attributes
| Name | Type | Value |
|---|---|---|
| X_ | ndarray[float64](105, 16) | [[ 5.1 , 2.5 , 3. ,...,-1.38,-0.32, 0.37], [ 6.2 , 2.2 , 4.5 ,..., 0.03, 0.03,-0.12], [ 5.1 , 3.8 , 1.5 ,...,-0.16,-1.06,-0.53], ..., [ 5.5 , 4.2 , 1.4 ,...,-0.27,-0.12, 0.83], [ 5.6 , 2.7 , 4.2 ,..., 0.04,-0.09, 0. ], [ 4.6 , 3.1 , 1.5 ,..., 0.22, 0.87, 0.22]] |
| best_estimator_ | Pipeline | Pipeline(step...m_state=42))]) |
| best_features_ | ndarray[bool](16,) | [False,False,False,...,False,False,False] |
| cv_results_ | dict | {'fe...es': [array([False,...False, True]), array([False,...False, False]), array([False,...False, False]), array([False,...False, False]), ...], 'me...me': [np.float64(0....1542561848958), np.float64(0....3043696085612), np.float64(0....5858917236328), np.float64(0.0790853500366211), ...], 'me...me': [np.float64(0....0404942830406), np.float64(0....5751190185547), np.float64(0....9554761250814), np.float64(0....9825617472332), ...], 'me...re': [np.float64(0.3451178451178451), np.float64(0.3122895622895623), np.float64(0.9612794612794614), np.float64(0....2929292929293), ...], ...} |
| estimator_ | Pipeline | Pipeline(step...m_state=42))]) |
| fit_stats_ | dict | {'ca...ts': 0, 'cr...ls': 182, 'du...es': 0, 'ev...es': 182, ...} |
| multimetric_ | bool | False |
| n_features_in_ | int | 16 |
| n_splits_ | int | 3 |
| refit_time_ | float | 0.00226 |
| scorer_ | _Scorer | make_scorer(b...hod='predict') |
| support_ | ndarray[bool](16,) | [False,False,False,...,False,False,False] |
| y_ | ndarray[int64](105,) | [1,1,0,...,0,1,0] |
Parameters
Fitted attributes
1 feature
| x0 |
Parameters
Fitted attributes
1 feature
| x3 |
Inspect Selected Features
The fitted selector exposes support_, just like many sklearn feature selectors. Because our input is a pandas DataFrame, we can recover the selected column names directly.
[5]:
selected_features = X_train.columns[selector.support_]
selected_summary = pd.DataFrame(
{
"feature": X_train.columns,
"selected": selector.support_,
"kind": ["original" if column in X_original.columns else "noise" for column in X_train.columns],
}
)
print(f"Selected {len(selected_features)} of {X_train.shape[1]} features")
selected_summary[selected_summary["selected"]]
Selected 1 of 16 features
[5]:
| feature | selected | kind | |
|---|---|---|---|
| 3 | petal width (cm) | True | original |
Read Fit Statistics and Telemetry
fit_stats_ summarizes search cost. history stores per-generation optimizer telemetry. These are useful when feature selection is slow or when the search converges too early.
[6]:
selector.fit_stats_
[6]:
{'evaluated_candidates': 182,
'unique_candidates': 182,
'cross_validate_calls': 182,
'cache_hits': 0,
'duplicate_candidates': 0,
'skipped_invalid_candidates': 0,
'population_parallel_batches': 6,
'population_serial_batches': 0,
'random_immigrants': 16,
'local_refinement_candidates': 2}
[7]:
history = pd.DataFrame(selector.history)
telemetry_columns = [
"gen",
"fitness",
"fitness_max",
"fitness_std",
"unique_individual_ratio",
"genotype_diversity",
"stagnation_generations",
"random_immigrants",
"local_refinement_candidates",
]
history[[column for column in telemetry_columns if column in history.columns]].tail()
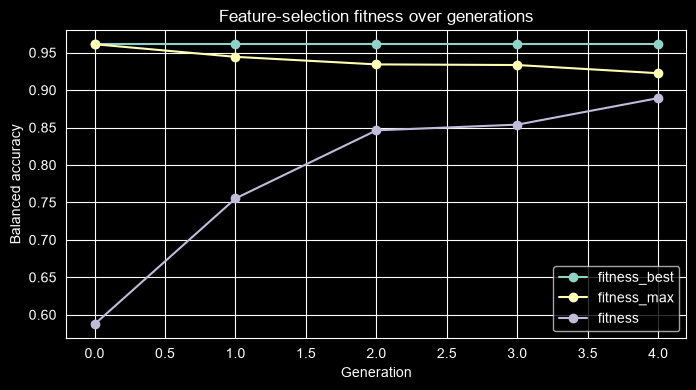
[7]:
| gen | fitness | fitness_max | fitness_std | unique_individual_ratio | genotype_diversity | stagnation_generations | random_immigrants | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0.587247 | 0.961279 | 0.273261 | 1.00 | 0.052632 | 0 | 0 |
| 1 | 1 | 0.755261 | 0.944444 | 0.199663 | 0.75 | 0.052632 | 1 | 4 |
| 2 | 2 | 0.846254 | 0.934343 | 0.108298 | 0.75 | 0.052632 | 2 | 4 |
| 3 | 3 | 0.853872 | 0.933502 | 0.080829 | 0.65 | 0.052632 | 3 | 4 |
| 4 | 4 | 0.889310 | 0.922559 | 0.025854 | 0.70 | 0.052632 | 5 | 4 |
[8]:
ax = history.plot(x="gen", y=["fitness_best", "fitness_max", "fitness"], marker="o", figsize=(8, 4))
ax.set_title("Feature-selection fitness over generations")
ax.set_xlabel("Generation")
ax.set_ylabel("Balanced accuracy")
[8]:
Text(0, 0.5, 'Balanced accuracy')
Compare Baseline and Selected-Feature Model
The selected-feature estimator supports the usual sklearn prediction API, so it can be evaluated just like the baseline pipeline.
[9]:
selector_metrics = evaluate(selector, X_test, y_test)
pd.DataFrame([baseline_metrics, selector_metrics], index=["all_features", "selected_features"])
[9]:
| accuracy | balanced_accuracy | |
|---|---|---|
| all_features | 0.822222 | 0.822222 |
| selected_features | 0.933333 | 0.933333 |
[10]:
print(classification_report(y_test, selector.predict(X_test), target_names=iris.target_names))
precision recall f1-score support
setosa 1.00 1.00 1.00 15
versicolor 0.88 0.93 0.90 15
virginica 0.93 0.87 0.90 15
accuracy 0.93 45
macro avg 0.93 0.93 0.93 45
weighted avg 0.93 0.93 0.93 45
Practical Notes
max_featuresis a useful way to make feature selection prefer compact solutions.If many candidates are skipped as invalid, increase
max_featuresor reduce mutation strength.If diversity drops quickly, use
diversity_control,random_immigrants_fraction, andfitness_sharingbefore simply increasing generations.Always compare with an all-feature baseline. A smaller selected subset is only useful if quality remains acceptable.