Pipeline Regression With GASearchCV
This notebook shows how to tune a scikit-learn Pipeline with GASearchCV. The objective is still pipeline prediction, but the example now includes a stronger regression workflow, holdout metrics, optimizer telemetry, and advanced optimizer controls.
Menu
Problem Setup
We use the diabetes regression dataset and tune a pipeline containing StandardScaler and GradientBoostingRegressor. Pipeline parameters use the usual sklearn double-underscore syntax, such as regressor__max_depth.
[1]:
import warnings
from pprint import pprint
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from sklearn.model_selection import KFold, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn_genetic import (
EvolutionConfig,
GASearchCV,
OptimizationConfig,
PopulationConfig,
RuntimeConfig,
)
from sklearn_genetic.callbacks import ConsecutiveStopping, DeltaThreshold, TimerStopping
from sklearn_genetic.plots import plot_fitness_evolution, plot_search_space
from sklearn_genetic.schedules import ExponentialAdapter, InverseAdapter
from sklearn_genetic.space import Categorical, Continuous, Integer
warnings.filterwarnings("ignore", category=UserWarning)
RANDOM_STATE = 42
[2]:
data = load_diabetes(as_frame=True)
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.30,
random_state=RANDOM_STATE,
)
cv = KFold(n_splits=4, shuffle=True, random_state=RANDOM_STATE)
print(f"Training shape: {X_train.shape}")
print(f"Test shape: {X_test.shape}")
Training shape: (309, 10)
Test shape: (133, 10)
Baseline Pipeline
A baseline gives us a sanity check before optimizing. The helper below returns common regression metrics where lower RMSE/MAE is better and higher R2 is better.
[3]:
def make_pipeline(**regressor_kwargs):
return Pipeline(
[
("scaler", StandardScaler()),
(
"regressor",
GradientBoostingRegressor(random_state=RANDOM_STATE, **regressor_kwargs),
),
]
)
def regression_metrics(estimator, X_eval, y_eval):
predictions = estimator.predict(X_eval)
rmse = mean_squared_error(y_eval, predictions) ** 0.5
return {
"r2": r2_score(y_eval, predictions),
"rmse": rmse,
"mae": mean_absolute_error(y_eval, predictions),
}
baseline = make_pipeline()
baseline.fit(X_train, y_train)
baseline_metrics = regression_metrics(baseline, X_test, y_test)
baseline_metrics
[3]:
{'r2': 0.43031868253825245,
'rmse': 55.45552342062193,
'mae': 44.71796061792019}
Define Pipeline Search Space
GASearchCV receives the same parameter names you would use with sklearn grid search. The values are sklearn-genetic-opt space objects instead of fixed grids or scipy distributions.
[4]:
param_grid = {
"regressor__n_estimators": Integer(40, 180),
"regressor__learning_rate": Continuous(0.01, 0.20, distribution="log-uniform"),
"regressor__max_depth": Integer(1, 4),
"regressor__min_samples_leaf": Integer(1, 12),
"regressor__subsample": Continuous(0.65, 1.0),
"regressor__loss": Categorical(["squared_error", "absolute_error", "huber"]),
}
Configure GASearchCV
This search uses performance and quality controls: smart initialization, warm starts, adaptive schedules, diversity control, fitness sharing, local refinement, cache reuse, and automatic parallel backend selection.
[5]:
search = GASearchCV(
estimator=make_pipeline(),
param_grid=param_grid,
scoring="neg_root_mean_squared_error",
criteria="max",
cv=cv,
evolution_config=EvolutionConfig(
population_size=12,
generations=10,
crossover_probability=ExponentialAdapter(initial_value=0.8, end_value=0.4, adaptive_rate=0.15),
mutation_probability=InverseAdapter(initial_value=0.25, end_value=0.08, adaptive_rate=0.25),
tournament_size=3,
elitism=True,
keep_top_k=3,
),
population_config=PopulationConfig(
initializer="smart",
warm_start_configs=[
{
"regressor__n_estimators": 100,
"regressor__learning_rate": 0.05,
"regressor__max_depth": 2,
"regressor__min_samples_leaf": 4,
"regressor__subsample": 0.85,
"regressor__loss": "squared_error",
}
],
),
runtime_config=RuntimeConfig(
n_jobs=-1,
parallel_backend="auto",
use_cache=True,
verbose=True,
return_train_score=False,
),
optimization_config=OptimizationConfig(
local_search=True,
local_search_top_k=2,
local_search_steps=1,
local_search_radius=0.20,
diversity_control=True,
diversity_threshold=0.30,
diversity_stagnation_generations=3,
diversity_mutation_boost=1.8,
random_immigrants_fraction=0.10,
fitness_sharing=True,
sharing_radius=0.40,
),
)
callbacks = [
DeltaThreshold(threshold=0.01, generations=5, metric="fitness_best"),
ConsecutiveStopping(generations=7, metric="fitness_best"),
TimerStopping(total_seconds=120),
]
search.fit(X_train, y_train, callbacks=callbacks)
gen evals avg best div unique stag mut sel events
---- ----- ------------- ------------- ------- ------- ----- ------- ----- ------------------
0 12 -61.14987 -59.23358 0.682 1.000 0 - - -
1 24 -60.65867 -59.23358 0.288 0.667 1 0.200 3 dup=3,share
2 24 -60.71806 -58.92132 0.364 0.750 0 0.256 3 div,imm=3,dup=10,s
3 24 -59.74359 -58.92132 0.303 0.667 1 0.193 3 dup=5,share
4 24 -59.91321 -58.92132 0.333 0.667 2 0.177 3 dup=10,share
5 24 -62.38514 -58.92132 0.409 0.667 3 0.165 3 dup=13,share
INFO: TimerStopping callback met its criteria
INFO: Stopping the algorithm
[5]:
GASearchCV(crossover_probability=<sklearn_genetic.schedules.schedulers.ExponentialAdapter object at 0x000002ACC9B397F0>,
cv=KFold(n_splits=4, random_state=42, shuffle=True),
diversity_control=True, diversity_mutation_boost=1.8,
diversity_stagnation_generations=3, diversity_threshold=0.3,
estimator=Pipeline(steps=[('scaler', StandardScaler()),
('regressor',
Gradi...
'regressor__min_samples_leaf': 4,
'regressor__n_estimators': 100,
'regressor__subsample': 0.85}]),
population_size=12, return_train_score=True,
runtime_config=RuntimeConfig(n_jobs=-1,
pre_dispatch='2*n_jobs',
error_score=nan,
return_train_score=False,
use_cache=True,
parallel_backend='auto',
verbose=True),
scoring='neg_root_mean_squared_error', sharing_radius=0.4)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| estimator | Pipeline(step...9516060816))]) | |
| cv | KFold(n_split... shuffle=True) | |
| param_grid | {'regressor__learning_rate': <sklearn_gene...002ACC9B39550>, 'regressor__loss': <sklearn_gene...002ACC9B39400>, 'regressor__max_depth': <sklearn_gene...002ACC9AEE350>, 'regressor__min_samples_leaf': <sklearn_gene...002ACC9AEE210>, ...} | |
| scoring | 'neg_root_mean_squared_error' | |
| population_size | 12 | |
| generations | 10 | |
| crossover_probability | <sklearn_gene...002ACC9B397F0> | |
| mutation_probability | <sklearn_gene...002ACC9B396A0> | |
| keep_top_k | 3 | |
| n_jobs | -1 | |
| return_train_score | True | |
| evolution_config | EvolutionConf...MuPlusLambda') | |
| population_config | PopulationCon...ared_error'}]) | |
| runtime_config | RuntimeConfig... verbose=True) | |
| optimization_config | OptimizationC...ction_cv=None) | |
| local_search | True | |
| local_search_top_k | 2 | |
| local_search_radius | 0.2 | |
| diversity_control | True | |
| diversity_threshold | 0.3 | |
| diversity_stagnation_generations | 3 | |
| diversity_mutation_boost | 1.8 | |
| fitness_sharing | True | |
| sharing_radius | 0.4 | |
| tournament_size | 3 | |
| elitism | True | |
| verbose | True | |
| criteria | 'max' | |
| algorithm | 'eaMuPlusLambda' | |
| refit | True | |
| pre_dispatch | '2*n_jobs' | |
| error_score | nan | |
| log_config | None | |
| use_cache | True | |
| warm_start_configs | None | |
| parallel_backend | 'auto' | |
| population_initializer | 'smart' | |
| local_search_steps | 1 | |
| random_immigrants_fraction | 0.1 | |
| adaptive_selection | False | |
| selection_pressure_min | 2 | |
| selection_pressure_max | None | |
| offspring_diversity_retries | 0 | |
| sharing_alpha | 1.0 | |
| final_selection | False | |
| final_selection_top_k | 3 | |
| final_selection_cv | None |
Fitted attributes
| Name | Type | Value |
|---|---|---|
| X_ | DataFrame | age... x 10 columns] |
| best_estimator_ | Pipeline | Pipeline(step...9516060816))]) |
| best_index_ | int | 133 |
| best_params_ | dict | {'re...te': 0.0875444183193989, 're...ss': 'sq...or', 're...th': 1, 're...af': 9, ...} |
| best_score_ | float | -58.82 |
| cv_results_ | dict | {'me...me': [np.float64(0.8632683157920837), np.float64(0.8658415079116821), np.float64(0.9247797131538391), np.float64(1.5119764804840088), ...], 'me...me': [np.float64(0....7496337890625), np.float64(0....9754371643066), np.float64(0....4149227142334), np.float64(0....6505546569824), ...], 'me...re': [np.float64(-60.31850154975417), np.float64(-6...4046828555245), np.float64(-5...3582652202905), np.float64(-60.21950347099971), ...], 'me...re': [np.float64(-4...3099979723964), np.float64(-2...0023997839722), np.float64(-5...0289346405715), np.float64(-5...7671444606044), ...], ...} |
| estimator_ | Pipeline | Pipeline(step...9516060816))]) |
| final_selection_results_ | dict | {'ca...es': [], 'changed': False, 'cv': None, 'enabled': False, ...} |
| fit_stats_ | dict | {'ca...ts': 1, 'cr...ls': 133, 'du...es': 0, 'ev...es': 134, ...} |
| multimetric_ | bool | False |
| n_features_in_ | int | 10 |
| n_splits_ | int | 4 |
| refit_time_ | float | 0.0728 |
| scorer_ | _Scorer | make_scorer(r...hod='predict') |
| y_ | Series[float64](309,) | 225 208.0 ...dtype: float64 |
Parameters
Fitted attributes
10 features
| age |
| sex |
| bmi |
| bp |
| s1 |
| s2 |
| s3 |
| s4 |
| s5 |
| s6 |
Parameters
Fitted attributes
Evaluate Predictions
GASearchCV refits the best pipeline, so you can call predict directly on the search object.
[6]:
print("Best CV negative RMSE:", round(search.best_score_, 4))
print("Best parameters:")
pprint(search.best_params_)
ga_metrics = regression_metrics(search, X_test, y_test)
pd.DataFrame([baseline_metrics, ga_metrics], index=["baseline", "ga_pipeline"])
Best CV negative RMSE: -58.8192
Best parameters:
{'regressor__learning_rate': 0.0875444183193989,
'regressor__loss': 'squared_error',
'regressor__max_depth': 1,
'regressor__min_samples_leaf': 9,
'regressor__n_estimators': 91,
'regressor__subsample': 0.7276569516060816}
[6]:
| r2 | rmse | mae | |
|---|---|---|---|
| baseline | 0.430319 | 55.455523 | 44.717961 |
| ga_pipeline | 0.498775 | 52.017011 | 41.412206 |
Inspect Search Cost and Telemetry
fit_stats_ summarizes evaluation mechanics. history stores generation-level telemetry, including diversity and stagnation fields.
[7]:
search.fit_stats_
[7]:
{'evaluated_candidates': 134,
'unique_candidates': 133,
'cross_validate_calls': 133,
'cache_hits': 1,
'duplicate_candidates': 0,
'skipped_invalid_candidates': 0,
'population_parallel_batches': 7,
'population_serial_batches': 0,
'random_immigrants': 3,
'local_refinement_candidates': 2}
[8]:
history = pd.DataFrame(search.history)
telemetry_columns = [
"gen",
"fitness",
"fitness_max",
"fitness_std",
"unique_individual_ratio",
"genotype_diversity",
"stagnation_generations",
"best_generation",
]
history[[column for column in telemetry_columns if column in history.columns]].tail()
[8]:
| gen | fitness | fitness_max | fitness_std | unique_individual_ratio | genotype_diversity | stagnation_generations | best_generation | |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | -60.658669 | -59.955816 | 0.461462 | 0.666667 | 0.287879 | 1 | 0 |
| 2 | 2 | -60.718057 | -58.921317 | 0.785379 | 0.750000 | 0.363636 | 0 | 2 |
| 3 | 3 | -59.743591 | -59.106876 | 0.587545 | 0.666667 | 0.303030 | 1 | 2 |
| 4 | 4 | -59.913208 | -59.106876 | 0.596168 | 0.666667 | 0.333333 | 2 | 2 |
| 5 | 5 | -61.326108 | -58.819157 | 1.757950 | 0.750000 | 0.409091 | 0 | 5 |
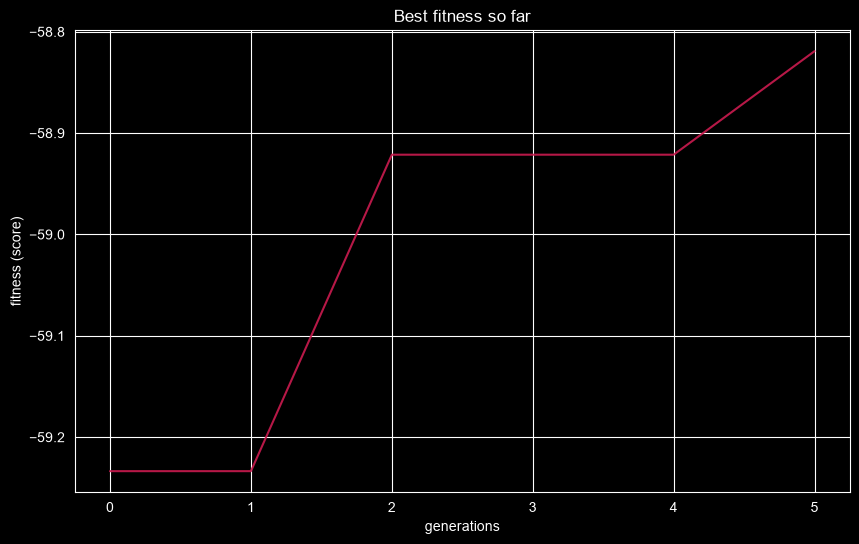
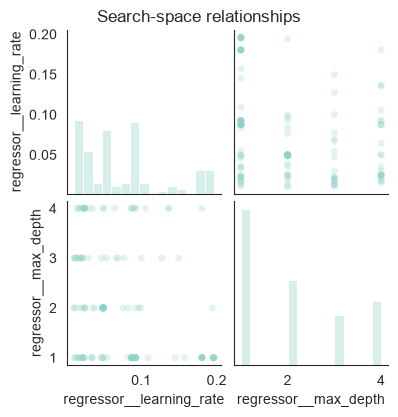
Visualize the Search
The plotting helpers work directly with fitted search objects. Use them for quick inspection, then rely on history and cv_results_ when you need custom reporting.
[9]:
plot_fitness_evolution(search)
[9]:
<Axes: title={'center': 'Best fitness so far'}, xlabel='generations', ylabel='fitness (score)'>
[10]:
plot_search_space(search, features=["regressor__learning_rate", "regressor__max_depth"])
plot_search_space(search, features=["regressor__learning_rate", "regressor__max_depth"])
[10]:
<seaborn.axisgrid.PairGrid at 0x2accadc3770>
Practical Notes
Use pipeline parameter names exactly as sklearn expects them.
For regression losses where larger is better only after negation, use sklearn’s negative scorers such as
neg_root_mean_squared_error.Compare holdout metrics, not only CV fitness.
If the search revisits many candidates, inspect
cache_hitsand consider stronger diversity controls or a larger search space.